
Wirekite Data
One-shot bulk migration. Terabytes in minutes.
Wirekite Data is the fastest way to move a database from one engine to another. Built for cloud migration projects where the whole team is on a deadline.
The initial-load problem.
The first move is always the hardest move. A 10 TB database doesn't
leave a single-threaded SELECT *
at any reasonable speed. The receiving warehouse can ingest 100× faster
than your source can produce — but only if you can feed it.
Off-the-shelf migration tools work through the source row by row, repackage every row into a bloated intermediate format, and feed the target one small batch at a time. Every hop is sequential and slow.
Wirekite Data is engineered to saturate every hop — it moves through each database's fastest native path and keeps the source and target decoupled, so neither side ever waits on the other.
How Wirekite Data works.
Extract
Read at the source's limit
Wirekite pulls every table through the fastest path the source allows, running as wide as the source can feed it.
Move
Source and target, decoupled
Data is staged in between, so neither side waits on the other — the source extracts and the target loads at the same time, each at its own top speed.
Load
Land at the target's limit
Data lands through the target's fastest native loading path, sized to fill its ingest capacity instead of trickling it in.
Watch the migration as it runs.
Live per-table throughput. Progress bars per object. No guessing.
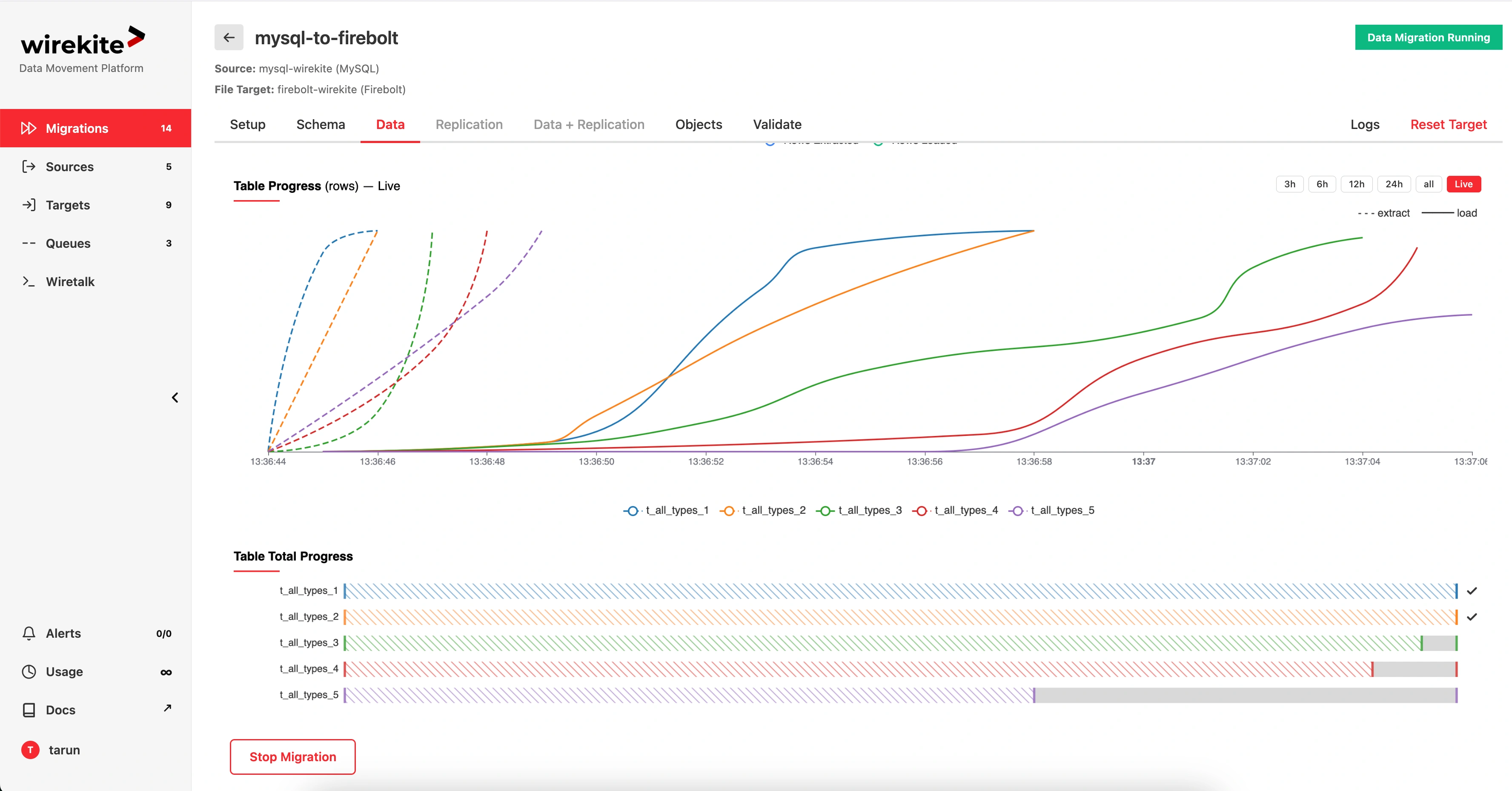
What the numbers look like.
Same hardware, real workloads, published methodology.
And after the load
Validate every row, source vs target.
Wirekite walks both sides sorted by primary key and compares column-by-column with type-aware logic. Not row counts. Not checksums. Every row.
See how validation works
Have a migration coming up?
We'll show you a 1 billion-row migration in real time.